3.7 Value Functions
Reinforcement learning algorithms involve estimating value functions that estimate how good it is for the agent to be in a given state. The how good notion is defined in terms of future rewards (or return) that can be expected.
Let the value of a state under a policy . It is the expected return when starting in and following thereafter. For MDPs, we can define it formally as:
where denotes the expected value of a random variable given that the agent follows policy , and t is any time step. We call the function the state-value function for policy .
Similarly, we define the value of taking action in state under a policy denoted as the expected return starting from , taking the action , and thereafter following policy :
We call the function the action-value function for policy
Theses function can be estimated from experience, by exploration. We call estimation methods of this kind Monte Carlo methods because they involve averaging over many random samples of actual returns. If there are very many states, then it may not be practical to keep separate averages for each state individually. Instead, the agent would have to maintain and as parameterized functions and adjust the parameters to better match the observed returns.
A fundamental property of value functions used throughout reinforcement learning and dynamic programming is thath they satisfy particular recursive relationship.
This equation is the Bellman equation for . It expresses a relationship between the value of a state and the values of its successor states.
Think of looking ahead from one state to its possible successor states. Starting from state s, the agent could take any of some set of actions. From each of these, the environment could respond with one of several next states along with a reward . The Bellman equation averages over all the possibilities, weighting each by its probability of occurring.
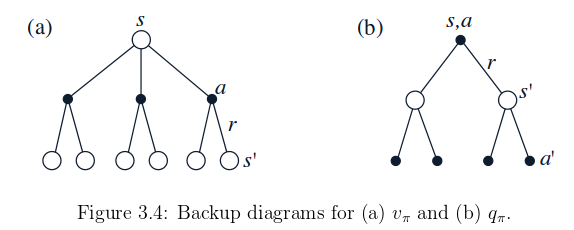
The value function is the unique solution to it's Bellman equation. We show in subsequent chapters how this Bellman equation forms the basis of a number of ways to compute, approximate, and learn .